

How To Normalize A Set Of Data
Before diving into this topic, lets first start with some definitions.
"Rescaling" a vector means to add or subtract a constant and and then multiply or divide past a constant, every bit you would do to change the units of measurement of the information, for example, to convert a temperature from Celsius to Fahrenheit.
"Normalizing" a vector most often means dividing by a norm of the vector. It also ofttimes refers to rescaling past the minimum and range of the vector, to brand all the elements lie between 0 and ane thus bringing all the values of numeric columns in the dataset to a common scale.
"Standardizing" a vector nearly often ways subtracting a measure of location and dividing past a measure of calibration. For example, if the vector contains random values with a Gaussian distribution, you might decrease the mean and divide by the standard departure, thereby obtaining a "standard normal" random variable with hateful 0 and standard deviation 1.
Afterwards reading this postal service you will know:
- Why should you lot standardize/normalize/scale your data
- How to standardize your numeric attributes to take a 0 mean and unit variance using standard scalar
- How to normalize your numeric attributes betwixt the range of 0 and one using min-max scalar
- How to normalize using robust scalar
- When to choose standardization or normalization
Allow's get started.
Why Should You Standardize / Normalize Variables:
Standardization:
Standardizing the features around the eye and 0 with a standard deviation of ane is important when we compare measurements that have different units. Variables that are measured at different scales do not contribute every bit to the analysis and might end upward creating a bais.
For example, A variable that ranges between 0 and 1000 will outweigh a variable that ranges betwixt 0 and 1. Using these variables without standardization will requite the variable with the larger range weight of 1000 in the analysis. Transforming the data to comparable scales tin can forestall this problem. Typical data standardization procedures equalize the range and/or information variability.
Normalization:
Similarly, the goal of normalization is to change the values of numeric columns in the dataset to a common scale, without distorting differences in the ranges of values. For machine learning, every dataset does not require normalization. Information technology is required only when features take unlike ranges.
For example, consider a data set containing ii features, historic period, and income(x2). Where historic period ranges from 0–100, while income ranges from 0–100,000 and higher. Income is virtually 1,000 times larger than historic period. So, these two features are in very dissimilar ranges. When we practice farther analysis, like multivariate linear regression, for example, the attributed income will intrinsically influence the consequence more due to its larger value. But this doesn't necessarily hateful it is more of import as a predictor. So we normalize the data to bring all the variables to the same range.
When Should Yous Utilize Normalization And Standardization:
Normalization is a good technique to utilise when you practise non know the distribution of your data or when you know the distribution is not Gaussian (a bong bend). Normalization is useful when your data has varying scales and the algorithm you are using does not make assumptions about the distribution of your data, such every bit k-nearest neighbors and artificial neural networks.
Standardization assumes that your data has a Gaussian (bell bend) distribution. This does not strictly take to be true, but the technique is more effective if your attribute distribution is Gaussian. Standardization is useful when your information has varying scales and the algorithm y'all are using does make assumptions virtually your data having a Gaussian distribution, such equally linear regression, logistic regression, and linear discriminant analysis.
Dataset:
I have used the Lending Guild Loan Dataset from Kaggle to demonstrate examples in this article.
Importing Libraries:
import pandas as pd import numpy every bit np import seaborn as sns import matplotlib.pyplot as plt
Importing dataset:
Permit's import three columns — Loan amount, int_rate and installment and the showtime 30000 rows in the data set (to reduce the computation time)
cols = ['loan_amnt', 'int_rate', 'installment'] data = pd.read_csv('loan.csv', nrows = 30000, usecols = cols) If you lot import the entire data, there will be missing values in some columns. Yous can just drop the rows with missing values using the pandas drib na method.
Basic Assay:
Let'due south at present analyze the bones statistical values of our dataset.
data.describe()
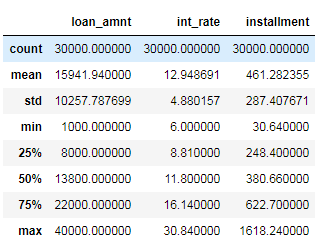
The unlike variables present unlike value ranges, therefore different magnitudes. Non but the minimum and maximum values are different, but they likewise spread over ranges of different widths.
Standardization (Standard Scalar) :
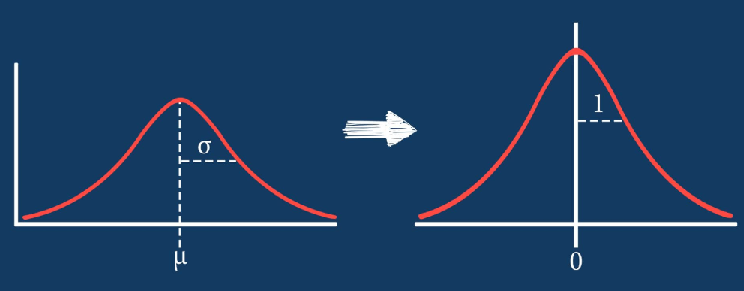
Every bit nosotros discussed earlier, standardization (or Z-score normalization) means centering the variable at zero and standardizing the variance at 1. The procedure involves subtracting the hateful of each observation and then dividing by the standard deviation:
The result of standardization is that the features will be rescaled so that they'll have the properties of a standard normal distribution with
μ=0 and σ=1
where μ is the mean (average) and σ is the standard deviation from the hateful.
CODE:
StandardScaler from sci-kit-learn removes the hateful and scales the data to unit variance. We can import the StandardScalar method from sci-kit larn and apply it to our dataset.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() data_scaled = scaler.fit_transform(information)
Now allow's bank check the mean and standard deviation values
print(data_scaled.hateful(axis=0)) print(data_scaled.std(axis=0))

As expected, the mean of each variable is now around zero and the standard deviation is set up to 1. Thus, all the variable values lie within the aforementioned range.
print('Min values (Loan Amount, Int charge per unit and Installment): ', data_scaled.min(axis=0)) print('Max values (Loan Amount, Int rate and Installment): ', data_scaled.max(centrality=0)) 
However, the minimum and maximum values vary according to how spread out the variable was, to brainstorm with, and is highly influenced by the presence of outliers.
Normalization (Min-Max Scalar) :
In this arroyo, the data is scaled to a stock-still range — usually 0 to 1.
In contrast to standardization, the cost of having this bounded range is that nosotros volition end upward with smaller standard deviations, which tin can suppress the consequence of outliers. Thus MinMax Scalar is sensitive to outliers.
A Min-Max scaling is typically washed via the post-obit equation:
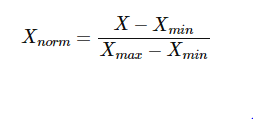
Code:
Let'due south import MinMaxScalar from Scikit-learn and apply it to our dataset.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() data_scaled = scaler.fit_transform(information)
At present let'south check the mean and standard deviation values.
print('means (Loan Amount, Int rate and Installment): ', data_scaled.mean(axis=0)) print('std (Loan Amount, Int rate and Installment): ', data_scaled.std(axis=0)) 
After MinMaxScaling, the distributions are non centered at zippo and the standard deviation is not 1.
print('Min (Loan Amount, Int rate and Installment): ', data_scaled.min(axis=0)) print('Max (Loan Amount, Int rate and Installment): ', data_scaled.max(axis=0)) 
But the minimum and maximum values are standardized beyond variables, different from what occurs with standardization.
Robust Scalar (Scaling to median and quantiles) :
Scaling using median and quantiles consists of subtracting the median to all the observations and and then dividing past the interquartile difference. Information technology Scales features using statistics that are robust to outliers.
The interquartile difference is the deviation betwixt the 75th and 25th quantile:
IQR = 75th quantile — 25th quantile
The equation to summate scaled values:
X_scaled = (X — 10.median) / IQR
CODE:
Offset, Import RobustScalar from Scikit learn.
from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data_scaled = scaler.fit_transform(data)
Now check the mean and standard deviation values.
impress('ways (Loan Corporeality, Int rate and Installment): ', data_scaled.mean(axis=0)) print('std (Loan Amount, Int charge per unit and Installment): ', data_scaled.std(axis=0)) 
Equally you lot can run into, the distributions are not centered in goose egg and the standard deviation is not 1.
print('Min (Loan Amount, Int rate and Installment): ', data_scaled.min(axis=0)) print('Max (Loan Amount, Int rate and Installment): ', data_scaled.max(axis=0)) 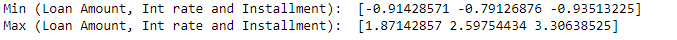
Neither are the minimum and maximum values set to a certain upper and lower boundaries like in the MinMaxScaler.
I promise you lot institute this article useful. Happy learning!
References
- https://www.udemy.com/feature-engineering-for-motorcar-learning/
- https://www.geeksforgeeks.org/python-how-and-where-to-utilise-characteristic-scaling/
How, When and Why Should You Normalize/Standardize/Rescale Your Information? was originally published in Towards AI — Multidisciplinary Scientific discipline Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI

How To Normalize A Set Of Data,
Source: https://towardsai.net/p/data-science/how-when-and-why-should-you-normalize-standardize-rescale-your-data-3f083def38ff
Posted by: andersontocke1979.blogspot.com
0 Response to "How To Normalize A Set Of Data"
Post a Comment